Аппаратный сбой
Аппаратный сбой
Даже хорошо проверенное, высоконадежное оборудование иногда отказывает, отправляя данные на тот свет. Все материальное со временем изнашивается, даже современные полупроводниковые схемы. Если такой отказ происходит тогда, когда база данных открыта, то данные можно потерять, даже не осознавая этого. Опыт показывает — рано или поздно это произойдет. Уж если закон Мерфи и проявляет себя, так только в самое неподходящее время.
Одним из способов защитить данные от отказов оборудования является резервное копирование. Сохраняйте лишние копии всего подряд. Если ваша организация может себе это позволить, для обеспечения максимальной безопасности можно продублировать аппаратные средства вместе с их настройками с таким расчетом, чтобы, если потребуется, можно было быстро установить и запустить резервные копии базы данных и приложений на резервном оборудовании. Ну а если ограниченность в средствах не позволяет дублировать все подряд, включая расходы? Тогда, по крайней мере, делайте достаточно часто резервные копии вашей базы данных и приложений — причем настолько часто, чтобы вам после неожиданного отказа не пришлось заново вводить слишком много данных.
Другой способ избежать наихудших последствий аппаратных сбоев — использование транзакций. Это основная тема данной главы. Транзакция — это неделимая единица работы. Или транзакция выполняется целиком, или не выполняется вовсе. Если этот подход "все или ничего" кажется вам слишком радикальным, примите к сведению, что самые большие проблемы возникают в результате неполного выполнения операции с базой данных.
Блокирование объектов базы данных
Ограничения в транзакциях
Проверка достоверности данных заключается не только в проверке правильности типа данных. Кроме этого, возможно, потребуется следить, чтобы в некоторых столбцах не было неопределенных значений, а в других — значения не выходили за границы определенного диапазона. Об этих ограничениях см. в главе 5.
Говорить о связи ограничений с транзакциями имеет смысл потому, что первые влияют на работу последних. Предположим, например, что нужно добавить данные в таблицу, в которой имеется столбец с ограничением NOT NULL. Как правило, в начале создают пустую строку и затем заполняют ее значениями. Однако ограничение NOT NULL не позволит воспользоваться данным способом, поскольку SQL не даст ввести строку с неопределенным значением, находящимся в столбце с ограничением NOT NULL, даже если данные
в этот столбец предполагается ввести еще до конца транзакции. Для решения этой проблемы в SQL:2003 существует возможность определять ограничения как DEFERRABLE (задерживаемые) или NOT DEFERRABLE (незадерживаемые).
Ограничения, определенные как NOT DEFERRABLE, применяются немедленно. А те, что определены как DEFERRABLE, первоначально могут быть заданы как DEFERRED (задержанные) или IMMEDIATE (немедленные). Если ограничение типа DEFERRABLE задано как IMMEDIATE, то оно действует так, как и ограничение типа NOT DEFERRABLE, — немедленно. Если же ограничение типа DEFERRABLE задано как DEFERRED, то его действие может быть отсрочено.
Чтобы добавлять пустые записи или выполнять другие операции, которые могут нарушить ограничения типа DEFERRABLE, можно использовать следующий оператор:
SET CONSTRAINTS ALL DEFERRED ;
Он определяет все ограничения типа DEFERRABLE как DEFERRED. На ограничения типа NOT DEFERRABLE этот оператор не действует. После того как выполнены все операции, которые могут нарушить ваши ограничения, и таблица достигла того состояния, когда их нарушать уже нельзя, тогда эти ограничения можно применить заново. Соответствующий оператор выглядит следующим образом:
SET CONSTRAINTS ALL IMMEDIATE ;
Если вы сделали ошибку и данные не соответствуют каким-либо ограничениям, вы сразу же это увидите после выполнения данного оператора.
Если ограничения, ранее заданные как DEFERRED, явно не задаются вами как IMMEDIATE, то, когда вы попытаетесь завершить свою транзакцию с помощью оператора COMMIT, SQL активизирует все задержанные ограничения. Если к этому моменту не все ограничения выполняются, транзакция будет отменена и SQL выдаст сообщение об ошибке.
Ограничения в SQL защищают от ввода неправильных данных (или, что так же важно, от недопустимого отсутствия данных), причем у вас есть возможность на время действия транзакции временно отменить имеющиеся ограничения.
Чтобы увидеть, насколько важна отсрочка применения ограничений, проанализируйте пример с платежными ведомостями.
Предположим, что в таблице EMPLOYEE (сотрудник) имеются столбцы EmpNo (номер сотрудника), EmpName (фамилия сотрудника), DeptNo (номер отдела) и Salary (оклад). DeptNo является внешним ключом, который ссылается на таблицу DEPT (отдел). Предположим также, что в таблице DEPT имеются столбцы DeptNo и DeptName (название отдела), причем DeptNo — это первичный ключ.
Представим, что, кроме этого, вы хотите иметь такую же таблицу, как и DEPT, но в которой еще есть столбец Payroll (платежная ведомость), и в нем для каждого отдела имеется сумма значений Salary сотрудников этого отдела.
Эквивалент этой таблицы можно создать с помощью следующего представления:
CREATE VIEW DEPT2 AS
SELECT D.*, SUM(E.Salary) AS Payroll
FROM DEPT D, EMPLOYEE E
WHERE D.DeptNo = E.DeptNo
GROUP BY D.DeptNo ;
Точно такое же представление можно определить еще и другим способом:
CREATE VIEW DEPT3 AS
SELECT D.*,
(SELECT SUM(E.Salary)
FROM EMPLOYEE E
WHERE D.DeptNo = E.DeptNo) AS Payroll
FROM DEPT D ;
Но предположим, что для большей эффективности вы не собираетесь вычислять значение SUM каждый раз, когда ссылаетесь на столбец DEPT.Payroll. Вместо этого вы хотите, чтобы в таблице DEPT в действительности находился столбец Payroll. Значения в этом столбце вы будете обновлять каждый раз, когда будете вносить изменения в столбце Salary.
И, чтобы обеспечить правильность значений в столбце Salary, в определение таблицы можно вставить ограничение:
CREATE TABLE DEPT
(DeptNo CHAR(5),
DeptName CHAR(20),
Payroll DECIMAL(15,2),
CHECK (Payroll = (SELECT SUM(Salary)
FROM EMPLOYEE E WHERE E.DeptNo = DEPT.DeptNo)));
Теперь предположим, что вам надо увеличить на 100 значение Salary сотрудника под номером 123. Это можно сделать с помощью следующего обновления:
UPDATE EMPLOYEE
SET Salary = Salary + 100
WHERE EmpNo = '123' ;
Кроме того, следует обновить таблицу DEPT:
UPDATE DEPT D
SET Payroll = Payroll + 100
WHERE D.DeptNo = (SELECT E.DeptNo
FROM EMPLOYEE E
WHERE E.EmpNo 423') ;
(Подзапрос используется для того, чтобы получить ссылку на значение DeptNo сотрудника с идентификационным номером 123.)
Но здесь имеется трудность: после каждого оператора ограничения проверяются. Теоретически должны проверяться все ограничения. Но на практике реализациями проверяются только те из них, которые относятся к значениям, измененным в ходе работы оператора.
После первого из двух последних операторов UPDATE реализация проверяет все ограничения, которые ссылаются на измененные им значения. В число этих ограничений входит то, которое определено в таблице DEPT, потому что оно относится к столбцу Salary таблицы EMPLOYEE, а значения в этом столбце изменяются оператором UPDATE. После выполнения первого оператора UPDATE это ограничение оказалось нарушенным. Допустим, что перед выполнением этого оператора база данных находится в полном порядке и каждое значение Payroll в таблице DEPT равно сумме значений Salary из соответствующих строк таблицы EMPLOYEE. Тогда, как только первый оператор UPDATE увеличит значение Salary, это равенство выполняться не будет. Такая ситуация исправляется вторым оператором UPDATE, после выполнения которого значения базы данных соответствуют имеющимся ограничениям. Но в промежутке между этими обновлениями ограничения не выполняются.
Оператор SET CONSTRAINTS DEFERRED дает возможность временно отключить все или только указанные вами ограничения. Действие этих ограничений будет задержано до тех пор, пока выполнится или оператор SET CONSTRAINTS IMMEDIATE, или один из двух операторов: COMMIT и ROLLBACK. Следовательно, в нашем случае перед оператором UPDATE и после него необходимо поместить операторы SET CONSTRAINTS:
SET CONSTRAINTS DEFERRED ;
UPDATE EMPLOYEE
SET Salary = Salary + 100
WHERE EmpNo = '123' ;
UPDATE DEPT D
SET Payroll = Payroll + 100
WHERE D.DeptNo = (SELECT E.DeptNo
FROM EMPLOYEE E
WHERE E.EmpNo = '123') ;
SET CONSTRAINTS IMMEDIATE ;
Эта процедура откладывает действие всех ограничений. Например, при вставке в DEPT новых строк первичные ключи проверяться не будут; т.е. вы удалили и ту защиту, которая, возможно, вам нужна. Поэтому следует явно указывать ограничения, которые надо задержать. Для этого при создании ограничений им следует давать имена:
CREATE TABLE DEPT
(DeptNo CHAR(5),
DeptName CHAR(20),
Payroll DECIMAL(15,2),
CONSTRAINT PayEqSumsal
CHECK (Payroll = SELECT SUM(Salary)
FROM EMPLOYEE E
WHERE E.DeptNo = DEPT.DeptNo)) ;
На ограничения с именами можно ссылаться индивидуально:
SET CONSTRAINTS PayEqSumsal DEFERRED ;
UPDATE EMPLOYEE
SET Salary = Salary + 100
WHERE EmpNo = '12 3' ;
UPDATE DEPT D
SET Payroll = Payroll + 100
WHERE D.DeptNo = (SELECT E.DeptNo
FROM EMPLOYEE E
WHERE E.EmpNo = 423') ;
SET CONSTRAINTS PayEqSumsal IMMEDIATE ;
Если для ограничения в операторе CREATE не указано имя, то SQL создает это имя неявно. Оно находится в специальных таблицах — таблицах каталога. Но все-таки лучше явно задавать имена ограничений.
Теперь предположим, что во втором операторе UPDATE в качестве значения возрастания вы по ошибке указали 1000. Это значение в операторе UPDATE является разрешенным, потому что имеющееся ограничение было отсрочено. Но при выполнении оператора SET CONSTRAINTS...IMMEDIATE будут проверяться указанные в нем ограничения. Если они не соблюдаются, то будет сгенерировано исключение. Но если вместо оператора SET CONSTRAINTS...IMMEDIATE выполняется оператор COMMIT, а ограничения не соблюдаются, то вместо оператора COMMIT выполняется оператор ROLLBACK.
Подведем итог. Временно отменять действие ограничений можно только внутри транзакции. Как только транзакция завершается, ограничения сразу же вступают в силу. Если использовать эту возможность правильно, то транзакция не создаст никаких данных, нарушающих какие-либо ограничения.
Защита данных
Глава 14. Защита данных
Использование транзакций SQL Одним
Внимание
Если вам нужны точные результаты, уровнем изоляции READ UNCOMMITED лучше не пользоваться.
Уровень READ UNCOMMITED можно использовать тогда, когда нужно статистически обрабатывать такие малоизменяющиеся данные: максимальная задержка в оформлении заказов; средний возраст продавцов, не выполняющих норму; средний возраст новых сотрудников.
Во многих подобных случаях приблизительной информации вполне достаточно; дополнительное снижение производительности, нужное для получения более точного результата, не оправдано.
Проблемы неповторяющегося чтения
Следующим, более высоким уровнем изоляции является READ COMMITED: изменение, производимое другой транзакцией, невидимо для вашей транзакции до тех пор, пока другой пользователь не завершит ее с помощью оператора COMMIT. Этот уровень обеспечивает лучший результат, чем READ UNCOMMITED, но он все-таки подвержен неповторяющемуся чтению — новой серьезной неприятности.
Для пояснения рассмотрим классический пример с наличными товарами. Пользователь 1 отправляет запрос в базу данных, чтобы узнать количество определенного товара, имеющееся на складе. Это количество равно десяти. Почти в то же самое время пользователь 2 начинает, а затем с помощью оператора COMMIT завершает транзакцию, которая записывает заказ на десять единиц того же товара, уменьшая, таким образом, его запасы до нуля. И тут пользователь 1, думая, что в наличии имеется десять единиц товара, пытается оформить заказ на пять единиц. Но и такого количества уже нет. Пользователь 2, по существу, опустошил склад. Первоначальная операция чтения, выполненная пользователем 1 по имеющемуся количеству, является неповторяющейся. Это количество изменили прямо под носом пользователя 1, и все предположения, сделанные на основе полученных им данных, являются неправильными.
Риск фиктивного чтения
Уровень изоляции REPEATABLE READ дает гарантию, что такой неприятности, как неповторяющееся чтение, уже не будет. Однако на этом уровне все равно часто происходит фиктивное чтение — неприятность, возникающая тогда, когда данные, читаемые пользователем, меняются в результате другой транзакции, причем меняются как раз во время чтения.
Предположим, например, что пользователь 1 отправляет на выполнение команду, условие поиска которой (предложение WHERE или HAVING) выбирает какое-либо множество строк. И сразу же после этого пользователь 2 выполняет, а затем с помощью оператора COMMIT завершает операцию, в результате которой данные, хранящиеся в одной из этих строк, становятся другими. Вначале эти данные удовлетворяли условию поиска, заданному пользователем 1, а теперь — нет. Или, возможно, некоторые строки, которые вначале этому условию не соответствовали, теперь вполне для него подходят. А пользователь 1, транзакция которого еще не завершена, и понятия не имеет об этих изменениях; само же приложение ведет себя так, как будто ничего не произошло. И вот несчастный пользователь 1 оправляет на выполнение еще один оператор SQL. В нем условия поиска те же самые, что и в первоначальном операторе, поэтому пользователь надеется, что получит те же строки, что и перед этим. Но вторая операция выполняется уже не с теми строками, что первая. В результате фиктивного чтения надежная информация оказалась негодной.
Тише едешь - дальше будешь
Уровню изоляции SERIALIZABLE не свойственны неприятности, характерные для остальных трех уровней. Одновременные транзакции с уровнем SERIALIZABLE будут выполняться не параллельно, а последовательно. Если вы задали этот уровень изоляции, то только отказы оборудования и программ могут привести к невыполнению транзакции, и зная, что ваша система работает корректно, можно не беспокоиться о правильности результатов операций с базой данных.
Конечно, наивысшая надежность имеет свою цену в виде уменьшения производительности, так что во всем нужно знать меру. В табл. 14.1 приведены четыре уровня изоляции и решаемые ими проблемы.
Таблица 14.1. Уровни изоляции и решаемые ими проблемы
| Уровень изоляции | Решаемые проблемы |
| READ UNCOMMITED | Нет |
| READ COMMITED | "Черновое" чтение |
| REPEATABLE READ | "Черновое" чтение |
| Неповторяющееся чтение | |
| SERIALIZABLE | "Черновое" чтение |
| Неповторяющееся чтение | |
| Фиктивное чтение |
Неявный оператор начала транзакции
Некоторые реализации требуют, чтобы о начале транзакции сообщалось явным образом с помощью специального оператора, такого как BEGIN (начало) или BEGIN TRAN (начало транзакции). Стандарт SQL:2003 этого не требует. Если еще никакая транзакция не начата и на выполнение отправляется команда SQL, то в системе, совместимой с SQL:20039, создается транзакция по умолчанию. Например, операторы CREATE TABLE, SELECT и UPDATE выполняются только в транзакции. Достаточно запустить один из них на выполнение, и начнется транзакция по умолчанию.
Оператор SET TRANSACTION
Время от времени для транзакции приходится использовать характеристики, отличные от устанавливаемых по умолчанию. Эти нестандартные характеристики можно задавать с помощью оператора SET TRANSACTION. Этот оператор должен быть первым оператором транзакции. Оператор SET TRANSACTION позволяет задавать режим, уровень изоляции и размер диагностики.
Чтобы изменить, например, все три характеристики, можно отправить на выполнение такую команду:
SET TRANSACTION
READ ONLY,
ISOLATION LEVEL READ UNCOMMITED,
DIAGNOSTICS SIZE 4 ;
Операторы данной транзакции не смогут изменить базу данных (режим READ ONLY). Кроме того, определен самый низкий и, следовательно, наиболее опасный уровень изоляции (READ UNCOMMITED). Для области диагностики выбран размер 4. Как видно, параметры подобраны таким образом, чтобы транзакция использовала поменьше системных ресурсов.
Теперь сравните предыдущую команду с этой:
SET TRANSACTION
READ WRITE,
ISOLATION LEVEL SERIALIZABLE,
DIAGNOSTICS SIZE 8 ;
Эти значения позволяют транзакции изменить базу данных, задают наивысший уровень изоляции и назначают большую область диагностики. Эта транзакция предъявляет гораздо более высокие требования к системным ресурсам. В зависимости от реализации указанные значения могут оказаться значениями по умолчанию. Естественно, в операторе SET TRANSACTION можно использовать и другие значения уровня изоляции и размера диагностики.
Совет 1
Совет 1
Не задавайте слишком высокий уровень изоляции. Может показаться, что для надежности всегда лучше выбирать значение SERILIZABLE. В зависимости от конкретной ситуации это может оказаться неплохой идеей. С другой стороны, не всем транзакциям требуется такой высокий уровень изоляции, очень снижающий общую производительность системы. Если во время транзакции не требуется модифицировать базу данных, смело задавайте режим READ ONLY. В общем, лучше обойтись без фанатизма.
Нестабильность платформы
Нестабильность платформы
Нестабильность платформы относится к таким неприятностям, которых даже быть-то не должно, но, увы, они существуют. Чаще всего она проявляется при запуске одного или множества новых и относительно непроверенных компонентов системы. Проблемы могуг "притаиться" в новом выпуске СУБД, в новой версии операционной системы или же в новом оборудовании. Проявляются они обычно тогда, когда вы запускаете очень важное задание. В результате система блокируется, а данные — портятся. И вам больше ничего не остается, кроме как ругать последними словами свой компьютер и тех, кто его сделал, — особенно, если не осталось резервной копии.
Одновременный доступ
Одновременный доступ
Представим, что программы и оборудование, с которыми вы работаете, проверены, данные введены правильно, приложения свободны от ошибок, а оборудование абсолютно надежно. Получается, что данным ничего не грозит? К сожалению, нет. Если несколько людей одновременно пытаются использовать одну и ту же таблицу из базы данных, создается ситуация одновременного доступа и их компьютеры соревнуются за право первоочередного доступа. Многопользовательские системы баз данных должны иметь возможность эффективно разрешать возникающие коллизии одновременного доступа.
не предусмотрен явный оператор
Оператор COMMIT Хотя в SQL: 2OO3 не предусмотрен явный оператор начала транзакции, но зато есть два опера-юра ее завершения: COMMIT и ROLLBACK. Первый из них используйте тогда, когда вы уже дошли до конца транзакции и собираетесь подтвердить изменения, внесенные в базу данных. В операторе COMMIT может находиться необязательное ключевое слово WORK (СОММТГ WORK означает "завершить работу")- Если при выполнении оператора COMMIT произойдет ошибка или системный сбой, возможно, потребуется выполнить откат транзакции и повторить ее снова.
Оператор ROLLBACK
В конце транзакции иногда требуется отменить изменения, внесенные во время этой транзакции, т.е. восстановить базу данных в том состоянии, в каком она была перед самым началом транзакции. Для этого можно воспользоваться оператором ROLLBACK, который является отказоустойчивым. Даже если во время его выполнения в системе произойдет аварийный сбой, то после перезагрузки оператор ROLLBACK можно запустить снова. И он должен восстановить базу данных в состоянии, в каком она была перед началом транзакции.
Последовательное выполнение исключает
Последовательное выполнение исключает нежелательные взаимодействии
Конфликт транзакций не происходит, если они выполняются последовательно. Главное — побыстрее занять очередь. Если невыполнимая транзакция пользователя 1 заканчивается перед началом транзакции пользователя 2, то функция ROLLBACK (откат) возвращает все товары, заказанные пользователем 1, делая их доступными во время транзакции пользователя 2. Если бы во втором примере транзакции выполнялись последовательно, то у пользователя 2 не было бы возможности изменить количество единиц любого товара, пока не закончится транзакция пользователя 1. Только после окончания транзакции пользователя 1 пользователь 2 сможет увидеть, сколько есть в наличии единиц требуемого товара.
Если транзакции выполняются последовательно, одна за другой, они не смогут друг с другом взаимодействовать и нежелательные последствия таких взаимодействий исключаются, Если результат одновременных транзакций будет таким же, как и при последовательном выполнении, то эти транзакции называются упорядочиваемыми (serializable).
Проблемы взаимодействия транзакций
Проблемы взаимодействия транзакций
Проблемы, связанные с одновременным доступом, возникают даже в относительно простых приложениях. Представьте, например, такой случай. Вы пишете приложение, которое предназначено для обработки заказов и включает в себя четыре таблицы: ORDER_MASTER (главная таблица заказов), CUSTOMER (таблица клиентов), LINE_ITEM (строка заказа) и INVENTORY (таблица с описанием товаров). Выполняются следующие условия.
В таблице ORDERJVlASTER первичным ключом является поле OrderNumber (номер заказа), а поле CustomerNumber (номер клиента) — внешним ключом, который ссылается на таблицу CUSTOMER. В таблице LINEJTEM первичным ключом является поле LineNumber (номер строки), а поле ItemNumber (идентификационный номер товара) — внешним ключом, который ссылается на таблицу INVENTORY, и, наконец, одним из ее полей является Quantity (количество). В таблице INVENTORY первичным ключом является поле ItemNumber; кроме того, в ней есть поле QuantityOnHand (количество в наличии). Во всех трех таблицах есть еще и другие столбцы, но они в этом примере не рассматриваются.Политика вашей компании состоит в том, чтобы каждый заказ или выполнять полностью, или не выполнять вовсе. Частичные выполнения заказов не допускаются. (Спокойно. Это же воображаемая ситуация.) Вы пишете приложение ORDER_PROCESSING (обработка заказа), которое должно обрабатывать в таблице ORDER_MASTER каждый новый заказ, причем делать это следующим образом. Приложение вначале определяет, возможна ли отгрузка всех заказанных товаров. Если да, то приложение оформляет заказ, соответственно уменьшая в таблице INVENTORY значение столбца QuantityOnHand и удаляя из таблиц ORDER JvlASTER и LINE_ITEM записи, относящиеся к этому заказу. Пока все хорошо. Ваше приложение должно обрабатывать заказы одним из двух способов.
Первый способ состоит в том, чтобы в таблице INVENTORY обрабатывалась запись, которая соответствует каждой записи таблицы LINEJTEM. Если значение в QuantityOnHand является достаточно большим, то приложение его уменьшит. Но если это значение меньше требуемого, выполняется откат транзакции. Это делается для того, чтобы можно было восстановить все изменения, уже внесенные в таблицу INVENTORY в результате обработки предыдущих строк таблицы LINEJTEM этого заказа. Второй способ состоит в том, что проверяется каждая запись таблицы INVENTORY, соответствующая какой-либо записи заказа, находящейся в таблице LINEJTEM. Если значения во всех этих записях таблицы INVENTORY достаточно большие, тогда выполняется их уменьшение.Если заказ выполним, большей эффективностью обладает первый способ, если же нет — второй. Таким образом, если большая часть заказов выполнима, необходимо использовать первый способ. В противном случае больше подойдет второй. Предположим, что это приложение установлено и запущено в многопользовательской системе, в которой нет достаточного управления одновременным доступом. Сразу же возникают следующие проблемы.
Пользователь 1 запускает обработку заказа с помощью первого способа. На складе находится 10 единиц товара 1, и все это количество требуется для выполнения заказа. После выполнения заказа количество товара 1 становится равным нулю. Вот тут-то и начинается самое интересное. Пользователь 2 запускает обработку небольшого заказа на одну единицу товара 1 и обнаруживает, что заказ оформить нельзя, так как на складе нет нужного количества этого товара. А так как заказ оформить нельзя, выполняется откат. В это время пользователь 1 еще пытается заказать пять единиц товара 37, но на складе их всего четыре. Поэтому и для заказа пользователя 1 также выполняется откат — этот заказ нельзя полностью оформить. И таблица
INVENTORY возвращается в состояние, в котором она была перед тем, как эти пользователи начали работать. Получается, что не оформлен ни один из заказов, хотя заказ пользователя 2 вполне можно было выполнить.
Второй способ не лучше, хотя и по другим причинам. Пользователь 1 может проверить все заказываемые товары и решить, что все они имеются. Но если в дело вмешается пользователь 2 и обработку заказа на один из этих товаров запустит до того, как пользователь 1 выполнит операцию уменьшения, то транзакция пользователя 1 может окончиться неудачно.
Угрозы целостности данных
Угрозы целостности данных
Киберпространство (в том числе ваша собственная сеть) может быть прекрасным местом для посещения, но для размещенных в нем данных это отнюдь не райский уголок. Данные могут быть повреждены или совсем испорчены самыми разными способами. В главе 5 рассказывалось о проблемах, возникающих в результате ввода неправильных данных, ошибок оператора, злонамеренного повреждения данных и одновременного доступа. "Неаккуратные" команды SQL и неправильно спроектированные приложения также могут повредить данные, и не нужно иметь много фантазии, чтобы представить, как это может произойти. Впрочем, данным угрожают и две очевидные опасности: нестабильность платформы и аппаратные сбои. В данном разделе как раз говорится об этих двух опасностях, а также о неприятностях, связанных с одновременным доступом.
Последовательное выполнение
Уменьшение уязвимости данных
Чтобы уменьшить шансы потери данных из-за несчастного случая или непредвиденного взаимодействия, можно принимать меры предосторожности на нескольких уровнях. Можно так настроить СУБД, чтобы она без вас принимала некоторые из этих мер. Вы даже иногда не будете знать о них. Кроме того, администратор базы данных может по своему усмотрению обеспечить и другие меры предосторожности. О них вы также можете быть либо осведомлены, либо нет. И наконец, как разработчик вы можете сами принять определенные меры предосторожности при написании кода. Можно избавить себя от большей части неприятностей, если выработать привычку автоматически придерживаться следующих простых принципов и всегда реализовывать их в своем коде или во время работы с базой данных. Использовать транзакции SQL. Обеспечить такой уровень изоляции, чтобы соблюдалось равновесие между производительностью и защитой. Знать, когда и как запускать транзакции на выполнение, блокировать объекты базы данных и выполнять резервное копирование.
Теперь поговорим об этих принципах подробно.
Никогда не выполняйте ответственное задание
Внимание
Никогда не выполняйте ответственное задание в системе, имеющей хотя бы один непроверенный компонент. Не поддавайтесь искушению немедленно перейти на только что появившуюся бета-версию СУБД или операционной системы, даже если эта версия предоставляет расширенную функциональность. По необходимости экспериментируйте с новым программным обеспечением на машине, полностью изолированной от рабочей сети.
Использование SQL в приложениях
Глава 15. Использование SQL в приложениях
Модульный язык
Модульный язык
Использовать SQL вместе с процедурным программным языком можно и по-другому — с помощью модульного языка. Благодаря ему вы сможете разместить все операторы SQL в
отдельном модуле SQL.
Помни: Модуль SQL— это список команд SQL. Каждая из этих команд вызывается процедурой SQL, и перед ней стоят имя процедуры, имена и типы ее параметров.
В каждой процедуре SQL находится не менее одного оператора SQL. В любом месте программы на базовом языке можно явно вызвать эту процедуру. Вызов процедуры SQL происходит так, как если бы она была подпрограммой, написанной на базовом языке.
Таким образом, создать модуль SQL вместе со связанной с ним программой на базовом языке — это, в сущности, просто написать вручную тот код, который получается после обработки препроцессором встроенного SQL-кода.
Встроенный SQL получил большее распространение, чем модульный. И хотя большинство поставщиков предлагают какой-либо вариант модульного языка, но мало кто из них в своей документации уделяет ему особое внимание. Впрочем, у модульных языков есть несколько преимуществ.
Так как SQL полностью отделен от процедурного языка, то для написания модулей можно нанять самых лучших программистов, работающих в SQL. И неважно, имеют они какой-либо опыт работы с процедурным языком или нет. На самом деле решение вопроса о том, какой процедурный язык использовать, можно даже отложить до того времени, пока не будут написаны и отлажены модули SQL. Программу на базовом языке может написать программист, не знакомый с SQL. Важнее всего то, что в процедурном коде не будет фрагментов SQL-кода, поэтому можно будет использовать отладчик, позволяющий сэкономить большое количество времени, которое приходится тратить на разработку. И снова оговоримся: то, что с одной точки зрения может выглядеть как преимущество, с другой может выглядеть как недостаток. Модули SQL отделены от процедурного кода, и если вы попытаетесь понять работу программы, то вам будет труднее это сделать, чем при использовании встроенного SQL.Несовместимость типов данных
Несовместимость типов данных
Другое препятствие к легкой интеграции SQL с любым процедурным языком состоит в том, что типы данных SQL отличаются от типов данных основных языков программирования. Это не должно вас удивлять, ведь даже типы данных одного процедурного языка отличаются от типов данных другого. Общего стандарта типов данных не существует. В ранних версиях SQL, предшествовавших SQL-92, одной из главных проблем была несовместимость данных. Однако в SQL-92 (а также в SQL: 1999 и SQL:2003) с этой проблемой справляется оператор CAST. Как с его помощью преобразовать тип элемента данных, поддерживаемый в процедурном языке, в тип, который используется SQL, см. в главе 8.
Объектноориентированные RADинструменты
Объектно-ориентированные RAD-инструменты
Используя современные RAD-инструменты, можно создавать сложные приложения и при этом не знать, как написать хотя бы одну строку кода на С, Pascal, COBOL или FORTRAN. Вместо того чтобы писать код, вы выбираете из библиотеки объекты и помещаете каждый из шх в нужное место на экране.
Помни: У объектов разных стандартных типов имеются характеризующие их свойства, а каждому типу объектов свойственны специальные события. С объектом можно также связать какой-либо метод. Метод — это процедура, написанная на процедурном языке. Впрочем, возможно создать очень сложные приложения, не написав при этом ни одного метода.
Хотя и можно написать сложные приложения, не пользуясь при этом процедурным языком, но SQL вам рано или поздно все же понадобится. SQL настолько богат выразительными средствами, что их трудно или даже невозможно выразить в объектной парадигме. Поэтому RAD-инструменты позволяют вставлять операторы SQL в объектно-ориентированные приложения. Примером объектно-ориентированной среды разработки, в которой можно работать с SQL, является Borland C++ Builder. Microsoft Access — это несколько другая среда разработки приложений, которая позволяет использовать язык SQL совместно с процедурным языком VBA.
В главе 4 описывалось создание таблиц базы данных с помощью приложения Access. Эти операции представляют собой лишь малую часть возможностей Access. Основная цель этого инструмента — разработка приложений, которые обрабатывают данные в таблицах базы данных. Разработчик помещает объекты в формы, а затем назначает им свойства, события и возможные методы. Для обработки форм и объектов используется код VBA, содержащий встроенный язык SQL.
Объявление базовых переменных
Объявление базовых переменных
Помни: Между программой, написанной на базовом языке, и кодом SQL должна передаваться информация. Для этого используются базовые переменные. Чтобы SQL признал эти переменные, их перед использованием необходимо объявить. Объявления находятся в сегменте объявлений, который расположен перед программным сегментом. Сегмент объявлений начинается со следующей директивы:
EXEC SQL BEGIN DECLARE SECTION ;
А конец этого сегмента отмечается с помощью такого выражения:
EХЕС SQL END DECLARE SECTION ;
Перед каждым оператором SQL должна стоять директива SQL EXEC. Конец сегмента SQL может быть отмечен директивой завершения. В языке COBOL такой директивой является '"END-EXEC", I в языке FORTRAN — это конец строки, а в языках Ada, С, Pascal и PL/1 — точка с запятой.
Объявления модулей
Объявления модулей
Синтаксис объявлений в модулях имеет такой вид:
MODULE [имя-модуля]
[NAMES ARE имя-набора-символов]
LANGUAGE (ADA|С|COBOL|FORTRAN|MUMPS I PASCAL IPLI|SQL}
[SCHEMA имя - схемы]
[AUTHORIZATION идентификатор-подтверждения-полномочий]
[объявления-временных-таблиц.. . ]
[объявления-курсоров.. . ]
[объявления-динамических-курсоров...]
процедуры...
Как видно, имя модуля не является обязательным. Но, вероятно, все-таки неплохо модуль как-то назвать, чтобы избежать слишком большой путаницы. Необязательное предложение NAMES ARE (имена) определяет набор символов, используемый для имен. Если этого предложения в объявлении не будет, то используется набор символов, установленный в вашей реализации по умолчанию. Предложение LANGUAGE (язык) сообщает модулю, на каком языке написаны программы, которые должны его вызывать. Компилятору надо обязательно знать, что это за язык. Ведь он собирается преобразовать команды SQL так, чтобы для вызывающей их программы они выглядели как подпрограммы, написанные на том же языке, что и сама эта программа.
Хотя оба предложения, SCHEMA (схема) и AUTHORIZATION (подтверждение полномочий), являются необязательными, непременно надо указать хотя бы одно из них. Можно также указать и оба сразу. Первое из них определяет схему по умолчанию, а второе — идентификатор подтверждения полномочий. Если зы его не укажете, то для предоставления вашему модулю полномочий СУБД будет использовать полномочия текущего сеанса. Если на выполнение операции, которую вызывает ваша процедура, у вас нет прав, то процедура не будет выполняться.
Совет 3
Совет 3
Если вашей процедуре нужны временные таблицы, то объявляйте их с помощью специального предложения объявлений временных таблиц. Объявляйте курсоры и динамические курсоры еще до того, как они будут использованы какой-либо процедурой. Объявление курсора после процедуры возможно в случае, если его будет использовать не она, а процедуры, объявленные после. Более подробная информация, относящаяся к курсорам, приведена в главе 18.
Преобразование типов данных
Преобразование типов данных
В зависимости от типов данных, поддерживаемых базовым языком и языком SQL, вам, воз-рсно, для преобразования некоторых из этих типов данных придется использовать оператор CAST. Можно использовать базовые переменные, которые были объявлены с помощью DECLARE SECTION. А когда в операторах SQL применяются имена этих переменных, то не надо забывать следующее: перед этими именами необходимо ставить двоеточие (:). Это как раз и делается в следующем примере с таблицей FOODS (продукты питания) со столбцами FOODNAME (название продукта), CALORIES (калории), PROTEIN (белки), FAT (жиры), CARBOHYDRATE (углеводы):
INSERT INTO FOODS
(FOODNAME, CALORIES, PROTEIN, FAT, CARBOHYDRATE)
VALUES
(: foodname, rcalories, .-protein, :fat, :carbo) ;
Процедуры модуля
Процедуры модуля
И наконец, после всех этих объявлений в модуле находятся его функциональные части — процедуры. У процедуры в модульном SQL есть имя, объявления параметров и выполняющиеся операторы SQL. Программа, написанная на процедурном языке, вызывает процедуру по ее имени и передает ей значения через объявленные параметры. Синтаксис процедуры следующий:
PROCEDURE имя-процедуры
(объявление-параметра [, объявление-параметра]...)
оператор SQL ;
[операторы SQL] ;
Объявление параметра должно иметь такой вид:
имя-параметра тип-данных
или такой:
SQLSTATE
Объявляемые вами параметры могут быть входными, выходными или теми и другими одновременно. SQLSTATE является параметром состояния, посредством которого выводится информация об ошибках. Чтобы подробнее разобраться с параметрами, обратитесь к главе 20.
Противоположные режимы работы
Противоположные режимы работы
При комбинировании SQL с процедурными языками немалая трудность состоит в том, что при работе с таблицами язык SQL сразу может обрабатывать целый их набор, в то время как процедурные языки — только одну строку. Иногда это не так уж и важно. Операции с наборами таблиц можно выполнять отдельно от операций со строками, используя каждый раз нужный инструмент. Однако в некоторых случаях приходится проверять все записи таблицы на соответствие определенным условиям и в зависимости от этого выполнять с ней те или иные действия. Для такого процесса требуются как мощные возможности SQL по извлечению данных, так и возможности условных переходов, имеющиеся у процедурных языков. Эту комбинацию возможностей можно достичь с помощью SQL-кода, встроенного в программу, написанную на обычном процедурном языке.
Сильные и слабые стороны процедурных языков
Сильные и слабые стороны процедурных языков
В противоположность SQL, процедурные языки легко оперируют с отдельными строками, позволяя разработчику приложения точно управлять способом обработки таблицы. Такое управление является очень большим достоинством процедурных языков. Впрочем, имеете» и слабая сторона подобного подхода. Разработчик приложения должен точно знать, каким образом данные хранятся в таблицах базы данных. Имеет значение порядок расположении строк и столбцов, и его приходится учитывать.
Благодаря своей природе процедурные языки являются очень гибкими, и с их помощью можно создавать удобные экраны ввода и просмотра данных. Кроме того, для вывода на печать можно создавать очень сложные отчеты, имеющие любую требуемую структуру.
Сильные и слабые стороны SQL
Сильные и слабые стороны SQL
Одной из сильных сторон языка SQL является получение данных. Если важная информация размещена где-то в однотабличной или многотабличной базе данных, то ее можно отыскать с помощью инструментов SQL. Этот язык не работает с отдельными строками или столбцами, поэтому вам не нужно знать порядок расположения в таблице строк или столбцов. Имеющиеся в SQL средства обработки транзакций гарантируют, что на операции, выполняемые с базой данных, не повлияют любые другие пользователи, которые одновременно с вами могут получить доступ к одним и тем же таблицам.
Однако одной из слабых сторон SQL является его недоразвитый пользовательский интерфейс. В SQL нет средств для форматирования вывода и генерации отчетов. Результат выполнения запроса передается на терминал построчно.
Иногда качество, которое в одном случае является достоинством, может в другом оказаться, наоборот, недостатком. Например, одна из сильных сторон языка SQL состоит в том, что он может работать сразу с целой таблицей. Сколько бы в таблице ни было строк: одна, сто или сто тысяч — нужные вам данные можно извлечь из нее с помощью единственного оператора SELECT. Однако SQL не может легко работать с каждой строкой индивидуально. Для этого придется использовать или курсоры, которые описаны в главе 18, или процедурный базовый язык.
SQL код в программе написанной на процедурном языке
SQL - код в программе, написанной на процедурном языке
Хотя на пути интеграции SQL с процедурными языками может возникать множество трудностей, эта задача выполнима. Во многих случаях эта интеграция — единственный способ решения поставленной задачи за разумное время. О трех методах подобной интеграции — встроенном SQL, модульном языке и инструментах RAD — кратко рассказывается в следующих разделах.
SQL в приложении
SQL в приложении
В главе 2 SQL был назван неполным языком программирования. Для использования в приложении язык SQL необходимо комбинировать с процедурным языком, таким как Pascal, FORTRAN, Visual Basic, С, C++, Java или COBOL. У SQL есть как сильные, так и слабые стороны. У процедурных языков, имеющих другую структуру, также есть сильные и слабые стороны, но не такие, как у SQL. К счастью, сильные стороны SQL обычно компенсируют слабость процедурных языков, а сильные стороны процедурных языков проявляются как раз там, где SQL оказывается не на высоте. Если совместно использовать процедурные языки с SQL, можно создать мощные приложения с широким набором возможностей. Недавно появились объектно-ориентированные RAD-инструменты, которые позволяют встраивать код SQL в приложения, создаваемые из объектов, а не с помощью написания процедурного кода. В качестве примера таких инструментов можно привести Delphi и C++ Builder.
Трудности совместного использования SQL с процедурным языком
Трудности совместного использования SQL с процедурным языком
Учитывая то, как достоинства SQL компенсируют недостатки процедурных языков и наоборот, имеет смысл комбинировать их таким образом, чтобы объединить их достоинства, а не недостатки. Чтобы реализовать такое объединение на практике, приходится преодолевать некоторые трудности.
В предыдущих главах мы часто
Внимание
В предыдущих главах мы часто использовали звездочку ('*') для краткого обозначения всех столбцов в таблице. Если в таблице много столбцов, то звездочка помогает уменьшить ввод кода. Если же SQL применяется в прикладной программе, лучше раз и навсегда от нее отказаться. После того как приложение будет написано, вы или кто-то другой, возможно, добавите в таблицу новые столбцы или удалите старые. Однако в таком случае меняется значение понятия "все столбцы". Ваше приложение, когда оно указывает с помощью звездочки "все столбцы", может получить не те столбцы, на которые рассчитывает. Такое изменение в таблице не окажет влияния на имеющиеся программы, пока для исправления ошибки или внесения какого-либо изменения эти программы не будут перекомпилированы. Тогда воздействие символа шаблона ('*') расширится на все имеющиеся столбцы. Это изменение может привести к аварийному завершению работы приложения, не связанному с текущей отладкой, или вызвать другие изменения, которые сделают отладку настоящим кошмаром.
Совет 1
Совет 1
Чтобы обезопасить себя, указывайте имена всех столбцов в явном виде, а не полагайтесь на символ звездочки.
Внимание
Хотя RAD-инструменты, подобные Access, могут помочь в создании высококачественных приложений за сравнительно короткое время, но обычно эти инструменты работают только на одной или на нескольких платформах. Например, Access работает только в операционной системе Microsoft Windows. He забывайте об этом, если хотите предусмотреть возможный перенос своих приложений на другую платформу. RAD-инструменты, такие как Access, являются предвестниками окончательного объединения процессов проектирования реляционных и объектно-ориентированных баз данных. При этом основные достоинства реляционного подхода и SQL сохранятся. К ним будет добавлена возможность быстрой — и сравнительно свободной от ошибок — разработки, свойственная объектно-ориентированному программированию.
Встроенный SQL
Встроенный SQL
Самый распространенный метод сочетания SQL с процедурными языками называется встроенным SQL. Как понятно из названия, операторы SQL вставляются в нужные места процедурной программы. Естественно, внезапно появившись в программе, написанной, скажем, на языке С, оператор SQL может стать неприятным сюрпризом для компилятора. По этой причине программы, в которых имеется встроенный SQL, перед компиляцией или интерпретацией пропускают через препроцессор. О встроенном SQL-коде препроцессор предупреждается директивой EXEC SQL.
В качестве примера использования встроенного SQL рассмотрим программу, написанную на языке Рго*С фирмы Oracle, являющемся вариантом языка С. Программа получает доступ к таблице с данными сотрудников компании, предлагает пользователю ввести имя сотрудника, а затем выводит зарплату и комиссионные этого сотрудника. Затем она предлагает ввести новые данные по зарплате и комиссионным этого же сотрудника и обновляет этими данными таблицу.
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
VARCHAR ename[10];
FLOAT salary, comm;
SHORT salary_ind, comm_ind;
EXEC SQL END DECLARE SECTION;
main ()
{
int sret; /* Возвращаемый код scanf */
/* Регистрация */
strcpy(uid.arr,"FRED"); /*Копировать имя пользователя */
uid.len=strlen(uid.arr);
strcpy(pwd.arr,"TOWER") ; */ Копировать пароль /*
pwd.len=strlen(pwd.arr);
EXED SQL WHENEVER SQLERROR STOP;
EXED SQL WHENEVER NOT FOUND STOP;
EXEC SQL CONNECT :uid;
printf("Соединение с пользователем: percents \n",uid.arr);
printf("Введите имя пользователя для обновления: ");
scanf("percents",ename.arr);
ename.len=strlen(ename.arr);
EXEC SQL SELECT SALARY,COMM INTO :salary,:cornm
FROM EMPLOY
WHERE ENAME=:ename;
printf("Сотрудник: percents оклад: percent6.2f комиссионные:
percent6.2f \n",
ename.arr, salary, comm);
printf("Введите новый оклад: ");
sret=scanf("percentf",&salary);
salary_ind =0; /* Инициализировать индикатор */
if (sret == EOF !! sret == 0)
salary_ind =-1; /* Установить индикатор отсутствия ввода */
printf("Введите новые комиссионные: ");
sret=scanf("percentf",&comm);
comm_ind =0; /* Инициализировать индикатор */
if (sret == EOF !! sret == 0)
comm_ind=-1; /* Установить индикатор отсутствия ввода */
EXEC SQL UPDATE EMPLOY
SET SALARY=:salary:salary_ind
SET COMM=:comm:comm_ind
WHERE ENAME=:ename;
printf("Данные сотрудника percents обновлены. \n",ename.arr);
EXEC SQL COMMIT WORK;
exit(0);
}
He надо быть экспертом по языку С, чтобы понять суть того, что и каким образом делает программа. Ниже приведена последовательность выполнения операторов.
SQL объявляет базовые переменные. Язык С контролирует процедуру регистрации пользователя. SQL активизирует обработку ошибок и соединяется с базой данных. Язык С запрашивает у пользователя имя сотрудника, которое помещает в переменную rename. Оператор SQL SELECT извлекает данные по зарплате и комиссионным указанного пользователя и сохраняет их в двух переменных базового языка, .salary и xomm. Далее язык С выводит имя сотрудника, его зарплату и комиссионные, а затем требует ввести новые значения зарплаты и комиссионных. Он также проверяет, введены ли требуемые значения, и если нет, то устанавливает индикатор отсутствия ввода. SQL обновляет данные в базе на основе новых значений. Язык С отображает сообщение о завершении операции. SQL завершает транзакцию, и С завершает выполнение программы.Совет 2
Совет 2
Смешивать команды двух языков так, как это делается здесь, можно благодаря препроцессору. Он отделяет операторы SQL от команд базового языка, помещая эти операторы в отдельную внешнюю процедуру. Каждый оператор SQL заменяется вызовом соответствующей внешней процедуры. Теперь за свою работу может приниматься компилятор этого языка. Способ, с помощью которого операторы SQL будут передаваться базе данных, зависит от реализации. Но вы как разработчик ни о чем таком беспокоиться не должны. Этим займется препроцессор. Вам надо лишь позаботиться о базовых переменных и совместимости типов данных.
Аплеты Java
Аплеты Java
Java — язык подобный C++ и разработанный Sun Microsystems специально для создания клиентских Web-расширений. После того как соединение между клиентом и сервером установлено, аплет загружается на клиентский компьютер и запускается на нем. Подходящий аплет, встроенный на HTML-страницу, позволит получить удобный доступ к данным сервера. Схема работы Web-приложения базы данных с аплетом Java на клиентском компьютере приведена на Рисунок 16.3.
ODBC и JDBC
Глава 16. ODBC и JDBC
Интерфейс ODBC
Интерфейс ODBC
Интерфейс ODBC— это стандартизированный набор определений, которые включают все необходимое для организации взаимодействия приложения и требуемой базы данных. Интерфейс ODBC определяет следующее.
Библиотека вызовов функций. Стандартный синтаксис SQL. Стандартные типы данных SQL. Стандартный протокол соединения с базой данных. Стандартные коды ошибок.Вызовы функций ODBC обеспечивают соединение приложения с сервером базы данных. выполнение операторов SQL и возврат результатов приложению.
Для того чтобы выполнить какое-либо действие с базой данных, необходимо использовать соответствующую команду SQL в качестве аргумента функции ODBC. При условии использования стандартного для ODBC синтаксиса SQL результат выполнения этой функции не зависит от того, какая база данных установлена на сервере.
JDBC
JDBC
JDBC (Java DataBase Connectivity— Java-интерфейс взаимодействия с базами данных) имеет как много общих черт с ODBC, так и несколько существенных отличий. Одно из отличий явствует из названия. Как и ODBC, JDBC — универсальный интерфейс к базе данных, не зависящий от источника данных на сервере. Разница в том, что клиентское приложение для JDBC может быть написано только на Java, а не на любом другом языке типа C++ или Visual Basic. Другое отличие состоит в том, что и Java, и JDBC с начала и до конца разрабатывались для использования в Internet.
Java — это полнофункциональный язык программирования, на котором создаются полноценные приложения для работы с базами данных для различных систем клиент/сервер. При этом приложение Java, работающее с базой данных через ODBC, очень похоже на ODBC-приложение, написанное на C++. Основная разница заключается в их работе в Internet или интранет.
Когда система функционирует в Internet, то условия ее работы отличаются от условий в системе клиент/сервер. Клиентская часть приложения, которая работает с Internet,— это браузер с минимальными вычислительными способностями. Эти способности должны быть увеличены, чтобы переложить на клиента часть работы с базой данных; и аплеты Java предоставляют такую возможность.
Аплет — это небольшое приложение, постоянно находящееся на сервере. Когда клиент соединяется по Internet с сервером, аплет загружается и запускается на клиентском компьютере. Аплеты Java разработаны таким образом, чтобы запускаться в "песочнице" (sandbox). "Песочница" — это определенное место в памяти клиентского компьютера, в котором выполняются аплеты Java. Аплет не может взаимодействовать с чем-нибудь вне "песочницы". Такая архитектура позволяет защитить клиентский компьютер от потенциально опасных аплетов, которые могут получить доступ к секретной информации или нанести данным серьезный вред.
Клиентские расширения
Клиентские расширения
Web-браузеры разрабатываются с целью создать простой и понятный интерфейс для любых Web-страниц. Программы Netscape Navigator, Microsoft Internet Explorer и Apple's Safari изначально не были предназначены для использования в качестве клиентской части базы данных, Чтобы добиться необходимого уровня взаимодействия с базой данных в Internet, необходимы дополнительные функциональные возможности. Для обеспечения этих возможностей были разработаны различные клиентские расширения. Эти расширения включают вспомогательные приложения, включаемые модули Netscape Navigator, управляющие элементы ActiveX, Java-аплеты и сценарии. Расширения общаются с сервером с помощью протокола HTTP на языке HTML. Любой HTML-код, который оперирует данными из базы, преобразуется серверным расширением в ODBC-совместимый SQL-код перед тем, как быть направленным к источнику данных.
Компоненты ODBC
Компоненты ODBC
Интерфейс ODBC состоит из четырех функциональных компонентов. Благодаря каждому из них достигается гибкость ODBC, позволяющая взаимодействовать любым ODBC-совместимым клиентам и серверам. ODBC интерфейс включает в себя четыре уровня.
Приложение. Это та часть ODBC, с которой непосредственно работает пользователь. Естественно, приложения могут быть не только в ODBC-совместимых системах. Однако включение приложения в интерфейс ODBC имеет свой смысл. Приложение должно быть написано с учетом использования в нем ODBC. Оно должно взаимодействовать с диспетчером драйвера в строгом соответствии со стандартом ODBC. Диспетчер драйвера. Это библиотека динамической компоновки (dinamic link library, DLL), обычно поставляемая Microsoft. Она загружает необходимые драйверы для системных источников данных (возможно, нескольких) и направляет вызовы функций приложения с помощью драйверов к соответствующим источникам данных. Диспетчер драйвера прямо управляет некоторыми вызовами функций ODBC, а также перехватывает и обрабатывает некоторые типы ошибок. Драйвер. В связи с тем, что источники данных могут отличаться друг от друга, причем в некоторых случаях весьма существенно, необходим способ преобразования стандартных вызовов функций ODBC в код конкретного источника данных. Этим занимается драйвер DLL. Каждый драйвер DLL получает вызовы функций посредством стандартного интерфейса ODBC и переводит их в код, понятный источнику данных. Как только источник данных возвращает результат, драйвер в обратном порядке преобразует его в стандартный для ODBC вид. Драйвер является основным элементом, который позволяет ODBC-совместимому приложению управлять структурой и содержимым ODBC-совместимого источника данных. Источник данных. Существует множество различных источников данных. Таким источником может быть база данных на основе реляционной СУБД, находящаяся на одном компьютере с приложением, или база данных на удаленном компьютере. В роли источника данных может выступать обходящийся без СУБД индексно-последовательный файл (ISAM file) на локальном или удаленном компьютере. Для каждого вида источников данных требуется свой драйвер.ODBC
ODBC
ODBC — это стандартный интерфейс между базой данных и приложением, взаимодействующим с ней. Наличие подобного стандарта позволяет приложению на клиентском компьютере получать доступ к любой базе данных на сервере, используя SQL. Единственное требование заключается в том, чтобы и клиентская, и серверная части поддерживали стандарт ODBC. ODBC 4.0 — текущая версия данного стандарта.
Приложение получает доступ к конкретной базе данных, используя специально разработанный под эту базу драйвер. Клиентская часть драйвера, работающая напрямую с приложением, должна соответствовать стандарту ODBC. Для приложения безразлично, какая СУБД установлена на сервере. Серверная часть драйвера адаптирована к конкретной базе данных. С использованием такой архитектуры приложения не только не нужно настраивать на определенную СУБД, а даже и знать не обязательно, какая именно СУБД используется. Драйвер скрывает различия между различными типами серверных частей СУБД.
ОDBC и Internet
ОDBC и Internet
Операции с базами данных в Internet кое в чем серьезно отличаются от операций с базами данных в среде клиент/сервер. Самое заметное отличие с точки зрения пользователя заключается в клиентской части системы, которая включает в себя интерфейс пользователя. В системе клиент/сервер интерфейс пользователя — это часть приложения, которое связывается с источником данных на сервере через ODBC-совместимые операторы SQL. В World Wide Web клиентской частью системы является Web-браузер, который взаимодействует с источником данных на сервере с помощью протокола HTTP посредством языка HTML (HyperText Markup Language).
Так как любой Web-пользователь имеет доступ к данным в Internet, открытие доступа к базе данных в Internet называется опубликованием базы данных. Теоретически база данных в Internet доступна гораздо большему количеству людей, чем база данных на сервере в локальной сети. Обычно даже неизвестно, кто они. Таким образом, размещение данных в Internet больше похоже на публикацию их по всему миру, нежели на распределение информации между несколькими сотрудниками. На Рисунок 16.1 приведены различия между системой клиент/сервер и системой на базе Web.
ODBC и интранет
ODBC и интранет
Интранет — это локальная или глобальная сеть, работающая как упрощенная версия Internet. Так как вся сеть интранет принадлежит одной организации, то, как правило, отсутствует необходимость в применении комплексных мер безопасности, таких как брандмауэры. Все инструменты, разработанные для создания приложений в Internet, также подходят для создания приложений для интранет. ODBC работает в интранет точно так же, как и в Internet. При наличии нескольких различных источников данных клиенты, использующие Web-браузеры и соответствующие клиентские и серверные расширения, могут взаимодействовать с этими источниками посредством SQL-кода, передаваемого с помощью HTTP и ODBC. Драйвер ODBC переводит SQL-код в собственный язык команд базы данных и выполняет его.
ODBC в среде клиент/сервер
ODBC в среде клиент/сервер
В среде клиент/сервер интерфейс между клиентской и серверной частью называется программным интерфейсом приложения (application programmer's interface, API). API может быть как специальным, так и стандартным. Специальным (proprietary) API называется интерес, созданный для работы с определенной серверной частью. Программой, которая формирует этот интерфейс, является драйвер, и в специальной системе он называется собственным драйвером (native driver). Собственный драйвер оптимизирован для работы с определенной клиентской частью и связанной с ней серверной частью источника данных. В связи с тем, что собственные драйверы настроены как для работы с приложением, так и с СУБД, они передают команды и информацию достаточно быстро и без задержек.
Совет 1
Совет 1
Если система клиент/сервер рассчитана на использование с определенным источником данных и заведомо не будет использовать другой, лучше воспользоваться собственным драйвером из поставки СУБД. С другой стороны, если система должна уметь работать с различными источниками данных, использование интерфейса ODBC избавит разработчика от выполнения огромного количества ненужной работы.
Каждый драйвер ODBC создан для работы с конкретным источником данных, однако у всех них одинаковый интерфейс с диспетчером драйверов. Любой драйвер, не оптимизированный для работы с конкретным клиентом, скорее всего проиграет в быстродействии собственному драйверу. Основным недостатком первого поколения драйверов ODBC была их плохая производительность по сравнению с собственными драйверами. Последние измерения, однако, показали, что производительность драйверов ODBC 4.0 вполне сравнима с производительностью собственных драйверов. На сегодняшний день технология достигла уровня, когда уже не нужно жертвовать производительностью ради преимуществ стандартизации.
Сценарии
Сценарии
Сценарии (scripts) — наиболее гибкий инструмент для создания клиентских расширений. Использование языка сценариев, такого как Netscape JavaScript или Microsoft VBScript, позволяет максимально контролировать происходящее на клиентском компьютере. С их помощью можно организовать проверку достоверности ввода в поля формы, что позволит отбраковывать неправильно заполненные формы еще на клиентском компьютере. Это сэкономит время пользователей и уменьшит загрузку сети. Как и аплеты Java, сценарии встроены в страницу HTML и выполняются при открытии пользователем страницы.
Серверные расширения
Серверные расширения
В системе на базе Web общение между клиентским компьютером и Web-сервером происходит с помощью HTTP. Серверное расширение — это компонент системы, который переводит HTML-текст в ODBC-совместимый SQL-код, после чего сервер базы данных связывается с источником данных и выполняет этот код. В обратном направлении источник данных пересылает результат запроса серверу базы данных и далее серверному расширению, которое преобразует результат запроса в форму, понятную Web-серверу. Затем данные отсылают к клиентскому компьютеру по Internet, и Web-браузер пользователя их отображает. На Рисунок 16.2 приведена схема подобной системы.
Система базы данных на основе Web с серверным расширением
Рисунок 16.2. Система базы данных на основе Web с серверным расширением

Система клиент/сервер в сравнении с системой на базе Web
Рисунок 16.1. Система клиент/сервер в сравнении с системой на базе Web

Управляющие элементы ActiveX
Управляющие элементы ActiveX
Управляющие элементы Microsoft ActiveX подобны модулям Netscape, но работают по другому принципу. ActiveX базируется на ранней технологии OLE, разработанной Microsoft. Netscape поддерживает ActiveX, а также некоторые другие популярные технологии Microsoft. Естественно, Microsoft Internet Explorer совместим с ActiveX. Под контролем Netscape и Microsoft сейчас находится большая часть рынка браузеров.
Включаемые модули Netscape Navigator
Включаемые модули Netscape Navigator
Модули Netscape Navigator (Netscape Navigator plug-in) так же, как и вспомогательные приложения, помогают обрабатывать информацию, которую не понимает браузер. От последних они отличаются тем, что совместимы только с браузерами Netscape и в большей степени интегрированы с данными браузерами. Подобная интеграция позволяет браузеру отображать файл еще до полной его загрузки. Это качество является серьезным преимуществом такого рода программ. Пользователь не обязан ждать конца загрузки, чтобы увидеть изображение. Большое и всевозрастающее количество модулей Netscape делает доступным воспроизведение звука, общение с другими пользователями, анимацию, видео и интерактивную трехмерную виртуальную реальность. Для нас главное, что некоторые из модулей обеспечивают доступ к удаленным базам данных в Internet.
Загружая исполняемый код из Internet,
Внимание
Загружая исполняемый код из Internet, вы подвергаетесь определенной опасности. Даже Java-аплеты могут оказаться не такими уж и безобидными. Поэтому будьте осторожны при загрузке исполняемого кода с подозрительных серверов. Как и ODBC, JDBC передает операторы SQL от клиентской части приложения (аплета), запускаемого на компьютере клиента, к источнику данных на сервере. Также JDBC служит для передачи результатов выполнения запросов или сообщений об ошибках от источника данных обратно приложению. Польза от JDBC заключается в том, что разработчик аплетов может использовать стандартный интерфейс JDBC, не заботясь о том, какая база данных находится на сервере. JDBC выполняет все преобразования, необходимые для правильного двустороннего взаимодействия.
Вспомогательные приложения
Вспомогательные приложения
Первые клиентские расширения назывались вспомогательными приложениями (helper application). Вспомогательное приложение — это самостоятельная программа, выполняющаяся на компьютере пользователя. Она не интегрирована в Web-страницу и не отображается в окне Web-браузера. Ее можно использовать как программу просмотра для графических файлов, формат которых не поддерживается браузером. Чтобы воспользоваться такой программой, ее необходимо установить. После загрузки рисунка подходящего формата браузер вызывает программу просмотра. Серьезным недостатком этого метода является то, что перед запуском вспомогательного приложения весь файл данных должен быть записан во временный файл. Таким образом, для больших файлов время ожидания заметно увеличивается.
Webприложение базы данных использующее аплет Java
Рисунок 16.3. Web-приложение базы данных, использующее аплет Java
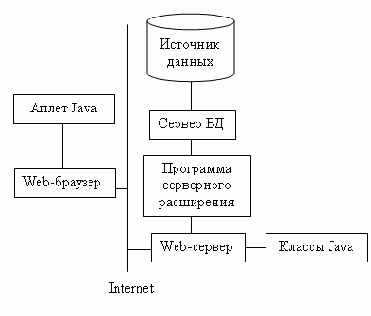
Преимущество использования аплетов Java заключается в том, что они не устаревают. Так как аплеты каждый раз при использовании загружаются с сервера, клиент всегда имеет дело с последней версией аплета. Разработчикам можно не беспокоиться о возможной потере совместимости при переходе сервера на новое программное обеспечение. Надо лишь убедиться в том, что загружаемые аплеты Java совместимы с новой конфигурацией сервера. Положительный ответ будет означать, что все клиенты также совместимы.
